I'm a principal research scientist at the Cosmos Lab at NVIDIA, working on world foundation models.
I received my PhD from University of California, Berkeley, advised by Professor Ravi Ramamoorthi and Alexei A. Efros.
My recent research focus is on using generative models to synthesize realistic images and videos, with applications to rendering, visual manipulations and beyond. See our NVIDIA Cosmos and NVIDIA Picasso (Edify) page.
@article{nvidia2025worldsimulationvideofoundation,
title = {World Simulation with Video Foundation Models for Physical AI},
author = {NVIDIA and others},
journal = {arXiv preprint arXiv:2511.00062},
year = {2025},
}
Cosmos-Predict2.5: World Simulation Model for Physical AI
@article{nvidia2025worldsimulationvideofoundationpredict2p5,
title = {World Simulation with Video Foundation Models for Physical AI},
author = {NVIDIA and others},
journal = {arXiv preprint arXiv:2511.00062},
year = {2025},
}
Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
@article{nvidia2025cosmostransfer1conditionalworldgeneration,
title = {Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control},
author = {NVIDIA and others},
journal = {arXiv preprint arXiv:2503.14492},
year = {2025},
}
Cosmos World Foundation Model Platform for Physical AI
@article{nvidia2025cosmosworldfoundationmodel,
title = {Cosmos World Foundation Model Platform for Physical AI},
author = {NVIDIA and others},
journal = {arXiv preprint arXiv:2501.03575},
year = {2025},
}
JeDi: Joint-image Diffusion Models for Finetuning-free Personalized Text-to-image Generation
@inproceedings{zeng2024jedi,
title={JeDi: Joint-image Diffusion Models for Finetuning-free Personalized Text-to-image Generation},
author={Zeng, Yu and Patel, Vishal M and Wang, Haochen and Huang, Xun and Wang, Ting-Chun and Liu, Ming-Yu and Balaji, Yogesh},
booktitle={CVPR},
year={2024}
}
DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion
@inproceedings{karras2023dreampose,
title={{Dreampose: Fashion image-to-video synthesis via stable diffusion}},
author={Karras, Johanna and Holynski, Aleksander and Wang, Ting-Chun and Kemelmacher-Shlizerman, Ira},
booktitle={ICCV},
year={2023}
}
SPACE: Speech-driven Portrait Animation with Controllable Expression
@inproceedings{gururani2022SPACE,
title={{SPACE: Speech-driven Portrait Animation with Controllable Expression}},
author={Siddharth Gururani and Arun Mallya and Ting-Chun Wang and Rafael Valle and Ming-Yu Liu},
booktitle={ICCV},
year={2023}
}
@inproceedings{mallya2022implicit,
title={{Implicit Warping for Animation with Image Sets}},
author={Arun Mallya and Ting-Chun Wang and Ming-Yu Liu},
booktitle={NeurIPS},
year={2022}
}
Generating Long Videos of Dynamic Scenes
Tim Brooks, Janne Hellsten, Miika Aittala, Ting-Chun Wang, Timo Aila, Jaakko Lehtinen, Ming-Yu Liu, Alexei A. Efros, Tero Karras
Conference on Neural Information Processing Systems (NeurIPS), 2022
@inproceedings{brooks2022generating,
title={Generating Long Videos of Dynamic Scenes},
author={Brooks, Tim and Hellsten, Janne and Aittala, Miika and Wang, Ting-Chun and Aila, Timo and Lehtinen, Jaakko and Liu, Ming-Yu and Efros, Alexei A and Karras, Tero},
booktitle=NeurIPS,
year={2022}
}
Learning to Relight Portrait Images via a Virtual Light Stage and Synthetic-to-Real Adaptation
@article{yeh2022learning,
title={Learning to Relight Portrait Images via a Virtual Light Stage and Synthetic-to-Real Adaptation},
author={Yu-Ying Yeh and Koki Nagano and Sameh Khamis and Jan Kautz and Ming-Yu Liu and Ting-Chun Wang},
journal={ACM Transactions on Graphics (TOG)},
year={2022}
}
Multimodal Conditional Image Synthesis with Product-of-Experts GANs
@inproceedings{huang2022poegan,
title={Multimodal Conditional Image Synthesis with Product-of-Experts {GANs}},
author={Xun Huang and Arun Mallya and Ting-Chun Wang and Ming-Yu Liu},
booktitle={ECCV},
year={2022}
}
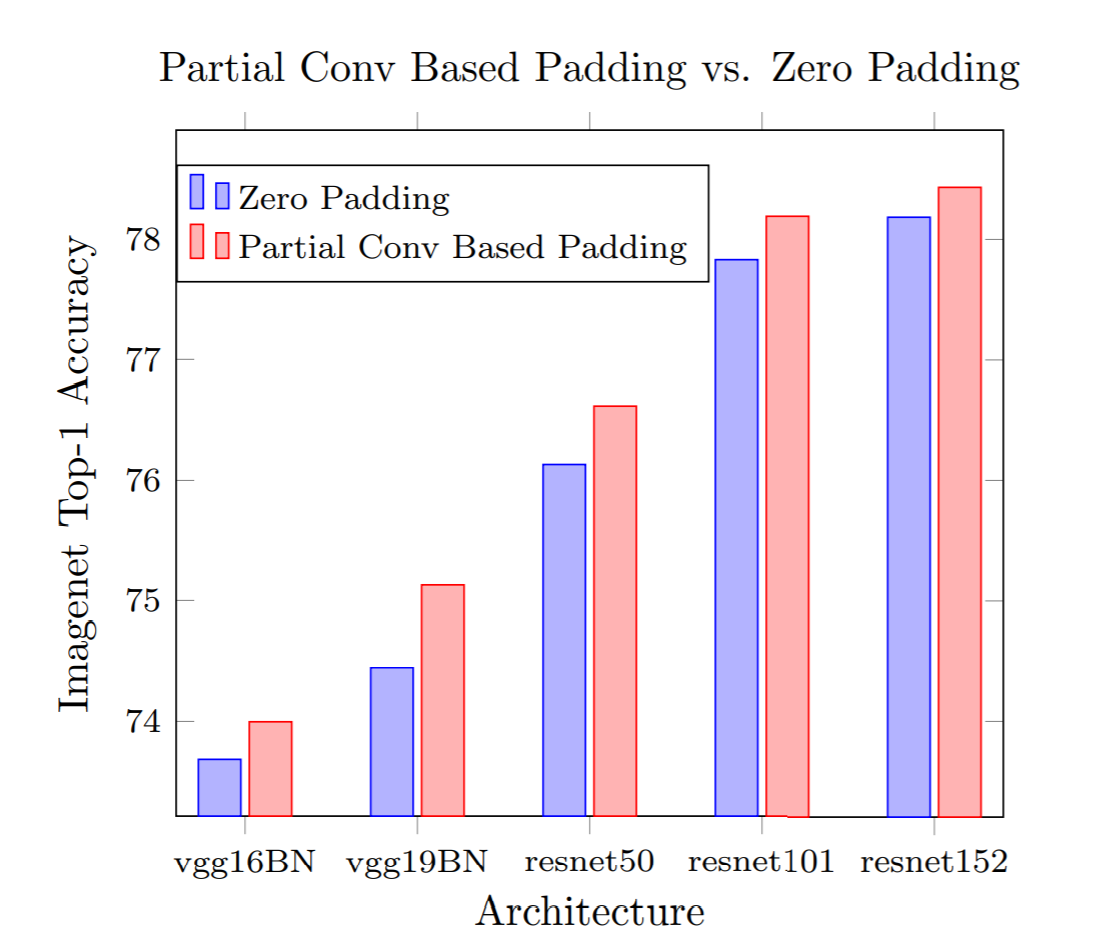
Partial Convolution for Padding, Inpainting, and Image Synthesis
@article{liu2022partial,
title={Partial Convolution for Padding, Inpainting, and Image Synthesis},
author={Liu, Guilin and Dundar, Aysegul and Shih, Kevin J. and Wang, Ting-Chun and Reda, Fitsum A. and Sapra, Karan and Yu, Zhiding and Yang, Xiaodong and Tao, Andrew and Catanzaro, Bryan},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2022},
}
One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing
@inproceedings{wang2021facevid2vid,
author = {Ting-Chun Wang and Arun Mallya and Ming-Yu Liu},
title = {One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year = {2021},
}
Transposer: Universal Texture Synthesis Using Feature Maps as Transposed Convolution Filter
@article{liu2021transposer,
author = {Guilin Liu and Rohan Taori and Ting-Chun Wang and Zhiding Yu and Shiqiu Liu
and Fitsum Reda and Karan Sapra and Andrew Tao and Bryan Catanzaro},
title = {Transposer: Universal Texture Synthesis Using Feature Maps as Transposed Convolution Filter},
journal = {ACM Transactions on Graphics},
year = {2021}
}
Generative Adversarial Networks for Image and Video Synthesis: Algorithms and Applications
@article{liu2021generative,
title={Generative Adversarial Networks for Image and Video Synthesis: Algorithms and Applications},
author={Ming-Yu Liu and Xun Huang and Jiahui Yu and Ting-Chun Wang and Arun Mallya},
journal={Proceedings of The IEEE},
year={2021}
}
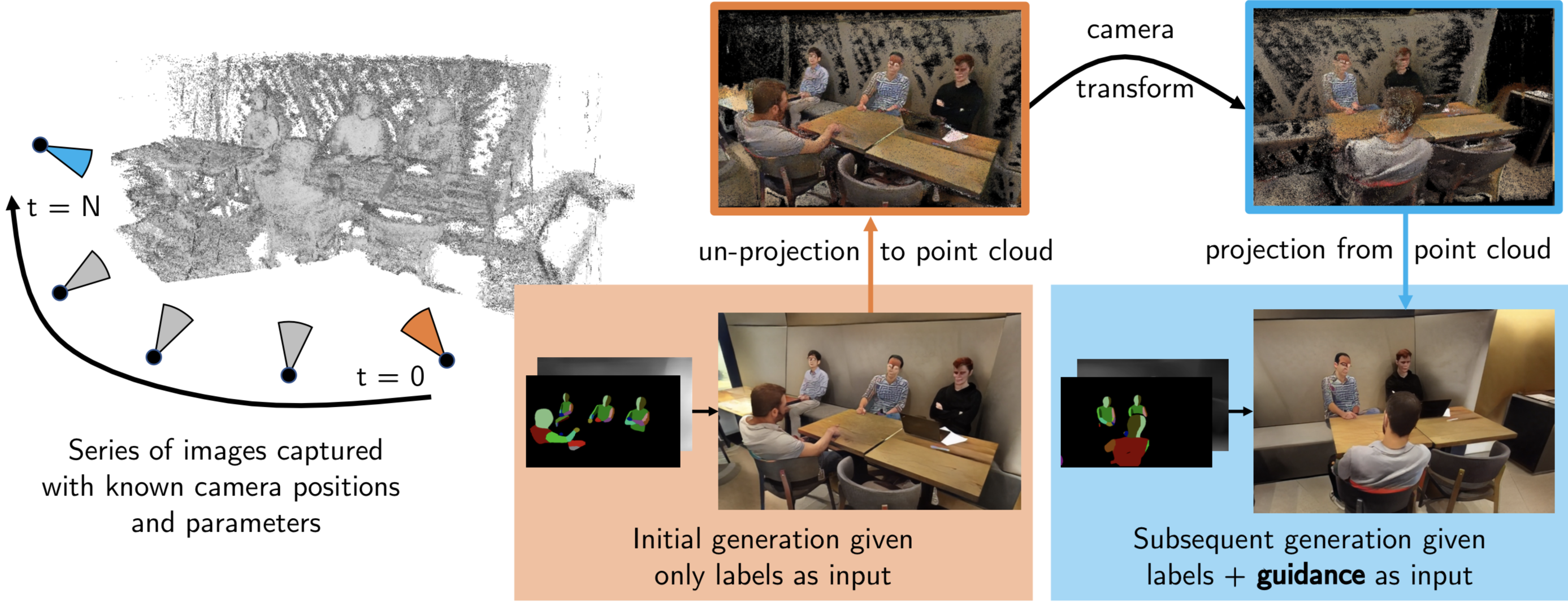
@inproceedings{mallya2020world,
author = {Arun Mallya and Ting-Chun Wang and Karan Sapra and Ming-Yu Liu},
title = {World-Consistent Video-to-Video Synthesis},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2020},
}
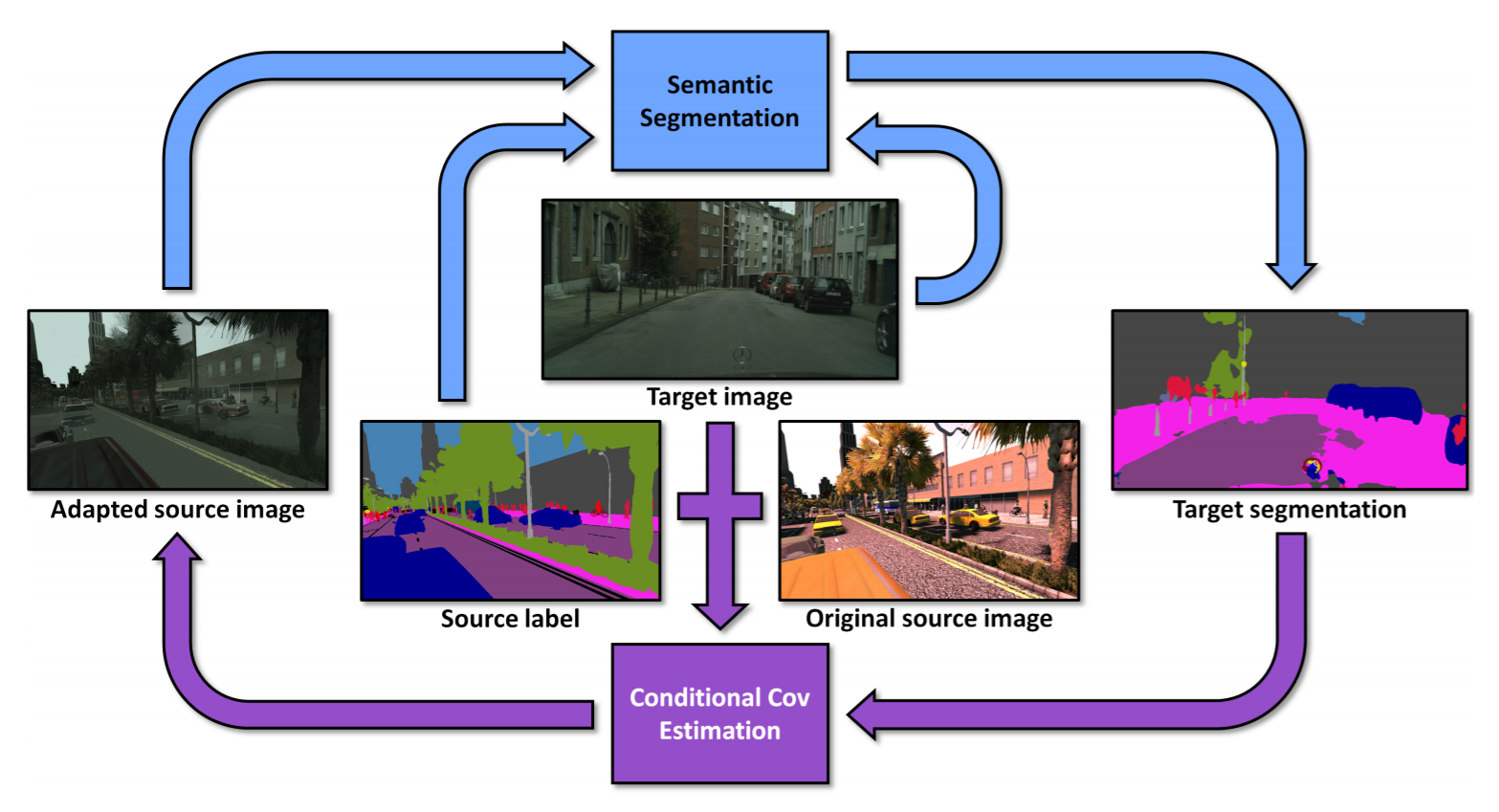
Domain Stylization: A Fast Covariance Matching Framework towards Domain Adaptation
@article{dundar2020domain,
title={Domain Stylization: A Fast Covariance Matching Framework towards Domain Adaptation},
author={Aysegul Dundar and Ming-Yu Liu and Zhiding Yu and Ting-Chun Wang and John Zedlewski and and Jan Kautz},
booktitle={IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
year={2020}
}
@inproceedings{wang2019fewshotvid2vid,
title={Few-shot Video-to-Video Synthesis},
author={Ting-Chun Wang and Ming-Yu Liu and Andrew Tao and Guilin Liu and Jan Kautz and Bryan Catanzaro},
booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
year={2019}
}
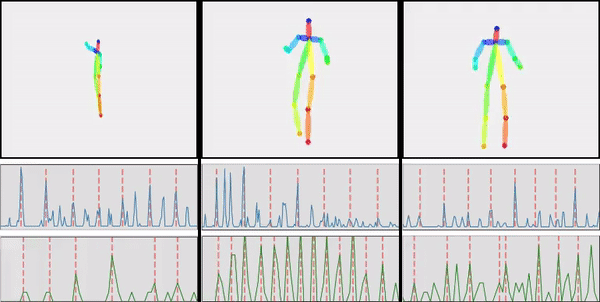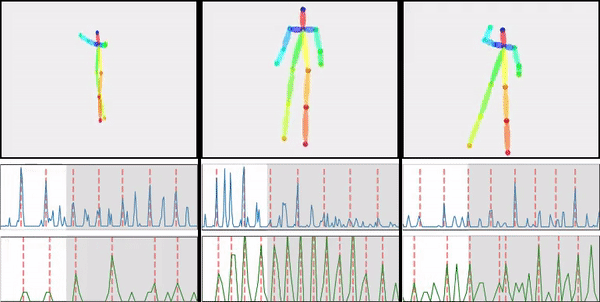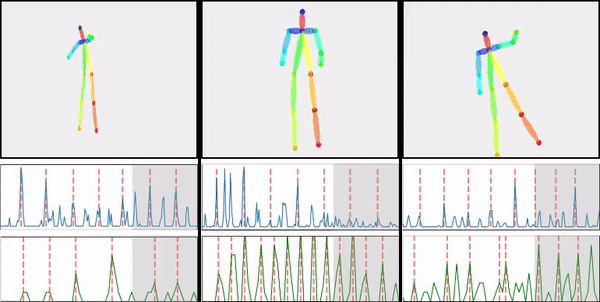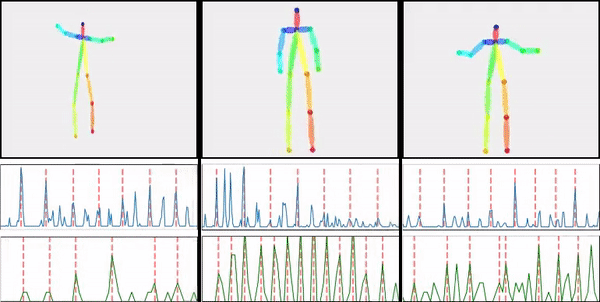
@inproceedings{lee2019dancing2music,
title={Dancing to Music},
author={Hsin-Ying Lee and Xiaodong Yang and Ming-Yu Liu and Ting-Chun Wang and Yu-Ding Lu and Ming-Hsuan Yang and Jan Kautz},
booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
year={2019}
}
Semantic Image Synthesis with Spatially-Adaptive Normalization
@inproceedings{park2019SPADE,
title={Semantic Image Synthesis with Spatially-Adaptive Normalization},
author={Park, Taesung and Liu, Ming-Yu and Wang, Ting-Chun and Zhu, Jun-Yan},
booktitle={Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR)},
year={2019}
}
@inproceedings{wang2018vid2vid,
author = {Ting-Chun Wang and Ming-Yu Liu and Jun-Yan Zhu and Guilin Liu
and Andrew Tao and Jan Kautz and Bryan Catanzaro},
title = {Video-to-Video Synthesis},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
year = {2018},
}
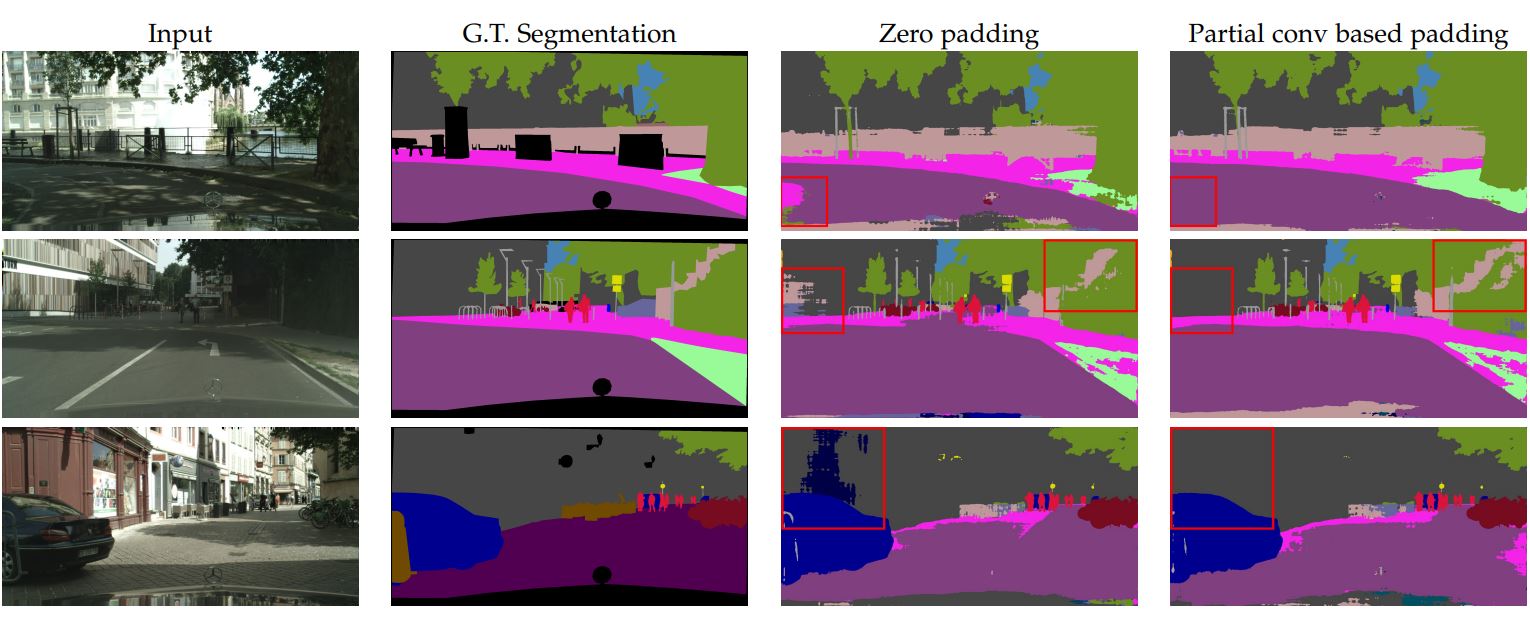
@article{liu2018partial,
author = {Liu, Guilin and Shih, Kevin J and Wang, Ting-Chun and Reda, Fitsum A
and Sapra, Karan and Yu, Zhiding and Tao, Andrew and Catanzaro, Bryan},
title = {Partial convolution based padding},
journal = {arXiv preprint arXiv:1811.11718},
year = {2018},
}
Domain Stylization: A Strong, Simple Baseline for Synthetic to Real Image Domain Adaptation
@article{dundar2018domain,
title={Domain Stylization: A Strong, Simple Baseline for Synthetic to Real Image Domain Adaptation},
author={Dundar, Aysegul and Liu, Ming-Yu and Wang, Ting-Chun and Zedlewski, John and Kautz, Jan},
journal={arXiv preprint arXiv:1807.09384},
year={2018}
}
Image Inpainting for Irregular Holes Using Partial Convolutions
@inproceedings{liu2018image,
author = {Liu, Guilin and Reda, Fitsum A and Shih, Kevin J
and Wang, Ting-Chun and Tao, Andrew and Catanzaro, Bryan},
title = {Image inpainting for irregular holes using partial convolutions},
booktitle = {Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2018},
}
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
@inproceedings{wang2018pix2pixHD,
author = {Ting-Chun Wang and Ming-Yu Liu and Jun-Yan Zhu
and Andrew Tao and Jan Kautz and Bryan Catanzaro},
title = {High-Resolution Image Synthesis and Semantic Manipulation
with Conditional GANs},
booktitle = {Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR)},
year = {2018},
}
Beyond Photo-Consistency: Shape, Reflectance, and Material Estimation Using Light-Field Cameras